
Generative AI Tools for Quantitative Research: A Practical Guide
Presenter(s): David Bann and Liam Wright
Generative Artificial Intelligence (GenAI)—systems that produce text, code, images and more—has advanced rapidly in recent years. Large language models (LLMs), like ChatGPT, have surged in capability.
Below we outline practical guidance for incorporating GenAI models into quantitative research workflows, focusing on coding. This should be useful to quantitative social scientists, but also to health researchers or data scientists more broadly. ‘Supporting Materials’ section includes links to further reading and guides on creating web visualisation tools and using local LLMs.
You may have already accessed services like ChatGPT through a web browser, copying and pasting syntax, but these can now be directly integrated into coding tools (e.g., Interactive Development Environments [IDEs] like VS Code, Positron, or RStudio).
LLMs help speed up conventional coding (e.g., via autocompletion) but also enable us to work at a higher level of abstraction. Researchers typically use high-level declarative languages (e.g., Python, R, or Stata), which software then executes using lower-level languages (ultimately, binary code). LLMs enable us to use plain language queries instead, with the LLM then generating code in whichever language is requested (Figure 1: AI enables data analysis at a higher level of abstraction – using plain English prompts.)
> Download Image description for accessibility.

Which model should I choose?
It’s not just ChatGPT – there are many, highly capable frontier-level LLMs, both closed and open weight (see Table 1). Weights are the learned parameters of an LLM that determine how inputs (prompts) are converted into outputs (text, code, images, etc.).
Closed-weight models are accessed via online services (apps, websites or API calls), meaning data are transmitted over the internet. Model weights are proprietary – inputs are sent and outputs returned, but the model is never exposed to the user. Close-weight model providers often have a free tier, though – to our minds – paid versions are more than worth the expense for regular data analysis work. Your university may already provide Microsoft Copilot, but in our experience, this does not work as well as directly using LLMs from the original provider (e.g., responses can be shortened, and not all models are available).
Open-weight models can be accessed online too, but also downloaded for free and run on local hardware. If run locally, no data is transmitted over the internet (unless, that is, internet browsing is used by the LLM to generate an output). This makes them suited to use for sensitive datasets, including within Trusted Research Environments.
Some models are specifically optimised to be able to run on laptops. They are smaller – and therefore less powerful – versions of the full models, though can still be useful for many generic coding tasks. Running them requires having enough RAM; if you have 16gb of RAM, models with 4 billion parameters or fewer will typically run. New laptops are being optimised for use with AI.
This is a field with intense and rapid competition. LMArena lets you compare and vote on two anonymous LLMs in a ‘battle’ and produces a leaderboard (with Elo rankings) of the best LLMs, an excellent resource for keeping up to date with the latest models. AI labs also score models against benchmark tests. Some of these benchmarks are being replaced with more difficult ones as models have improved enough to achieve perfect marks. Different LLMs have different properties – we recommend exploring multiple LLMs and, for complex prompts, using multiple LLMs iteratively.
Table 1. Selected frontier LLMs (companies).
| Closed weight LLMs | Open weight variant | Open weight LLMs |
| ChatGPT (OpenAI US) | ChatGPT-OSS (OpenAI US) | Deepseek (Deepseek CN) |
| Gemini (Google US) | Gemma (Google US) | Kimi k2 (Moonshot AI CN) |
| Claude (Anthropic US) | n/a | Mistral (Mistral AI FR) |
| Grok (xAI US) | Earlier Grok releases (xAI US) | Qwen (Alibaba Qwen CN) |
| Llama (Meta US) | ||
| Ernie (Baidu CN) | ||
| GLM (Zhipu AI CN) |
Note: Generally, training data are not made available, thus open weight models are partly yet not fully open source.
How to use LLMs for coding
The growing number of AI coding tools can be confusing, but they exist on a continuum of autonomy. At one end of the spectrum are assistants where the user is firmly in control—for example, accepting an autocomplete suggestion that the user then executes themselves (see Github Copilot). At the other end are agentic tools that take high-level prompts and can both generate and execute code to complete (possibly complex and extended) tasks.
The diagram below provides a visual breakdown of this landscape.
> Download Image description for accessibility.

It’s an area of rapid development and how we use LLMs may change in future; the internet may be actively altered to make it easier for LLMs to operate and as LLMs improve (i.e., make fewer mistakes), they will be able to successfully complete tasks involving longer sequences of steps.
But at present, we think the risk of errors (“hallucinations”) is too high to use LLMs to perform data analyses purely agentically (i.e., without any human oversight), especially given that health and social science data are often idiosyncratic and are less than perfectly documented. The LLM frontier is also ‘jagged’ – the quality of outputs is related to the quality and quantity of the data used to train the model; aptitude with more abundantly documented languages (e.g., R) is better than with others (e.g., Stata, Mplus). Researchers should critically appraise any code or methods recommended by LLMs.
Videos 1-3 show different ways of incorporating AI tools into quantitative research workflows, including using local LLMs for sensitive data which cannot be sent to cloud providers. It highlights VS Code, a popular and well-developed IDE which supports multiple coding languages and is particularly excellent for Python and R code.
Stata user? At the time of writing, the Stata app does not have full autocomplete nor Copilot functionality. Stata users can either copy and paste code directly into the Stata app or use VS Code with extensions to enable Stata language recognition and code execution (see link). Our experience is that this does not work as well as for Python or R.
General tips when using LLMs for quantitative research
Keeping up to date with developments: the field is moving rapidly with new models and software to use the models. See Further Reading section with links to newsletters.
Remain actively involved in the process (i.e., don’t trust outputs completely given errors [hallucinations] and output biases).
Handle sensitive data with care (e.g., individual level survey datasets are not typically permitted to be uploaded onto cloud-provided LLMs: mitigations including using simulated data instead, asking for generic code to then adapt using the sensitive data, or use local models).
Use principles of prompt engineering to get the most helpful outputs from your prompts and consider which model is best for your request (‘reasoning’ models, especially in Deep Research mode, are overpowered and unnecessarily slow for straightforward requests).
See this guide on AI and research integrity. Note that LLMs can recapitulate biases found in the human-generated knowledge base.
Video 1: Obtaining code via chatbots in R and Stata languages
Using chatbots
Cloud providers: closed weights (ChatGPT), open weights (Deepseek)
Local LLM, open weight: Ollama (gemma4b)
Prompts:
Give me R syntax which: 1) Describes the variables education and depression + plots them. 2) analyses the association between education and depression. Assume my data is called cohort-data.csv
The same in Stata format.
Video 2: Illustration of using LLMs to edit R scripts in VS Code
Models used:
Cloud providers: closed weights (ChatGPT 4.1)
Local LLM, open weight: Ollama (gemma4b)
Video 3: agentic analyses using command line interfaces
(Claude Code).
Using cohort-data.csv + R….
1) Describe the variables education and depression + plots them.
2) analyses the association between education and depression. 3) Create a visually compelling combined plot which includes both distributions and regression analyses e.g., estimates and 95% CI.
Video 4: an applied example
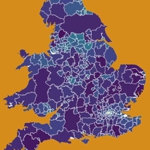
In Video 4 we showcase how LLMs can be used to (a) widen the variety of analyses a researcher is able to perform and (b) accelerate the speed at which the code is written and analyses completed. The example shown uses an LLM (Anthropic’s Claude) within the Positron IDE (an IDE that is particularly well suited with using R) to help write code that creates a map of crime rates across England and Wales. Neither of us is a geographer, but we generated the map in just a few minutes! What a time to be alive. We hope this gives researchers inspiration to increase the ambitiousness of their research.

About the author
David Bann is a Professor of Population Health at University College London. His work focuses on the distribution and determinants of population health. As well as research, he also contributes to the continued scientific development of cohort studies.
Liam Wright is a Lecturer in Statistics and Survey Methodology at UCL’s Social Research Institute. His research interests are in causal inference, genetic epidemiology, and methods for analysing mixed-mode survey data.
Their recent work on AI includes a recent NCRM Futures Briefing note, and work on the automation of epidemiology. They are also co-leads of an ongoing AI skills project led by NCRM.
- Published on: 22 September 2025
- Event hosted by: University College London
- Keywords: Artificial intelligence | large language models | coding | statistical analysis | data visualisation | Large language models | Coding |
- To cite this resource:
David Bann and Liam Wright. (2025). Generative AI Tools for Quantitative Research: A Practical Guide. National Centre for Research Methods online learning resource. Available at https://www.ncrm.ac.uk/resources/online/all/?id=20859 [accessed: 12 January 2026]
⌃BACK TO TOP