
It seems that everywhere we look, researchers are applying machine learning (ML) and artificial intelligence (AI) to new fields. But what about qualitative analysis? Is there a potential for software to help a researcher in coding qualitative data and understanding emerging themes and trends from complex datasets?
Firstly, why would we want to do this? The power of qualitative research comes from uncovering the unexpected and unanticipated in complex issues that defy easy questions and answers. Quantitative research methods typically struggle with these kind of topics, and machine learning approaches are essentially quantitative methods of analysing qualitative data. However, while machines may not be ready to take the place of a researcher in setting research questions and evaluating complex answers, there are areas that could benefit from a more automated approach. Qualitative analysis is time consuming and hence costly, greatly limiting where it is utilised. Training a computer system to act as a guide for a qualitative researcher wading through large, long or longitudinal qualitative datasets could open many doors.
Few qualitative research projects have a secondary coder who independently reads, analyses and checks interpretations, but an automated tool could perform this function, giving some level of assurance and suggesting quotes or topics that might have been overlooked.
Qualitative researchers could use larger data sources if a tool could speed up the work. While in qualitative research we aim to focus on the small, often this means focusing on a narrow population group or geographical area. With faster coding tools, we could design research using the same resources that includes more diverse populations, showing how universal trends are. It could also facilitate secondary analysis: qualitative research generates huge amounts of detailed data that is typically only used to answer one set of research questions. ML tools could help explore existing qualitative datasets with new research questions, getting increased value from archived and/or multiple sets of data.
I’m also excited about the potential for including wider sources of qualitative data in research projects. While most researchers go straight to interviews or focus groups with respondents, analysing policy or media on the subject would help understand the culture and context of a research issue.
With an interdisciplinary team from the University of Edinburgh, we experimented with current ML tools to see how feasible these approaches are. We analysed qualitative datasets with conventional ‘off-the-shelf’ Natural Language Processing (NLP) tools to try and do ‘categorisation’ tasks where researchers defined the ‘topics’, and the software assessed which sentences were relevant to each topic. Even in the best performing approach, there was only a 20% agreement rate with how researchers had previously coded the data. However this was not far off the agreement rate of a second human coder, who was not involved with the research project and only had the topics to code to. In this respect, the researcher was put in the same situation as the computer.
ML algorithms work best when they have thousands, or millions, of sources in which to identify patterns. Typical qualitative research projects may only have a dozen or less sources, so the approaches generally give weak results. However, the accuracy could be improved by pre-training the model with other related datasets and techniques we are investigating.
There are also limitations in the way the ML approaches work - while you can provide a coding framework of topics you are interested in, you can’t explain to the algorithm what your research questions are, and so what aspects of the data is interesting to you. ML might highlight how often your respondents talked about different flavours of ice cream, but if your interest is in healthy eating, this may not be very helpful.
Finally, even when the ML is working well, it’s difficult to know why. In deep learning approaches where the algorithm is self-training, the designers of the system can’t see how it works, creating a ‘black box’ [1]. This is problematic because we can’t see the decision making process and tell if a few unusual pieces of data are skewing the process, or if it is making basic mistakes like confusing two different meanings of words like ‘mine’.
There is a potential here for a new field that meets the quantitative worlds of big data with insight from qualitative questions. It’s unlikely that these tools will remove the researcher’s primary role in analysis, and there will always be questions that are best met with a purely manual qualitative approach. However, for the right research and data sets, it could open the door to new approaches and even more nuanced answers.
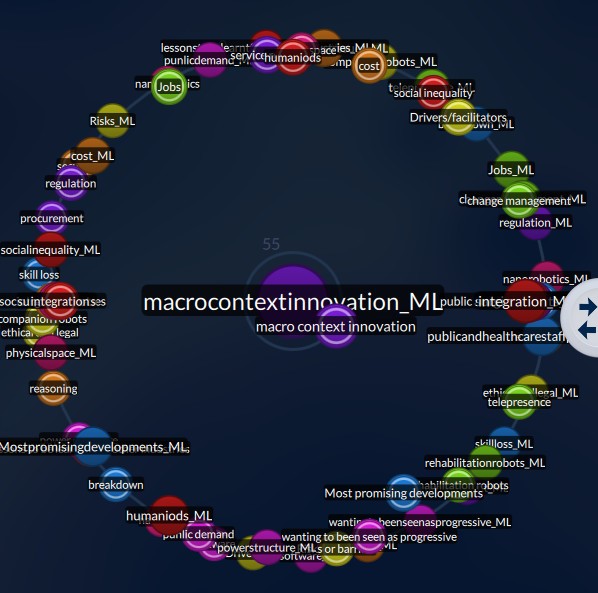
Figure 1: Visualisations in Quirkos allow the user to quickly see how well automated coding correlates with their own interpretations
This article is based on collaborative research with Claire Grover, Claire Lewellyn, and the late Jon Oberlander at the Informatics department, University of Edinburgh with Kathrin Cresswell and Aziz Sheikh from the Usher Institute of Population Health Sciences and Informatics, University of Edinburgh. It first appeared as a blog post on http://bigqlr.ncrm.ac.uk/, the website for the NCRM-funded project ‘Working across qualitative longitudinal studies: a feasibility study looking at care and intimacy’. The project was part funded by the Scottish Digital Health & Care Institute.
References:
[1] [[https://www.technologyreview.com/s/604087/the-dark-secret-at-the-heart-of-ai/]].